I’ve been building microservices in Go and Mongo for work these past few years, and I’ve found that these two work great together. It’s great at letting you quickly build out new services, with the flexibility of a schemaless DB and the rigidity of a strongly typed and highly concurrent language. That’s why I decided to use Go and Mongo when building out Inboxes.app, my disposable email Chrome extension.
My main gripe with Mongo in general is the hosting. It’s very expensive for what you get. mLab, the main competitor to MongoDB Atlas was bought out a few years ago by Mongo. They charge $15/gb for shared, or $180/mo for 2 GB. MongoDB Atlas charges $57/mo for 10GB which is more reasonable, but at $684 a year for a side project, that starts to get expensive. Sure there’s Shared which is cheaper, but I found my latency wasn’t all that great.
In comes Serverless
Serverless is a fantastic looking product by Atlas which seems to fit the bill. It starts at $0.30/m reads. You can use as much or as little as you want, and the pricing is – to be fair – reasonable.
I moved my mongodb instance from my dedicated server which was also hosting nginx and the custom smtp server to MongoDB Serverless and immediately set up alerting and billing alerts. We’ve all seen those horror stories, and I was not going to be one of them.
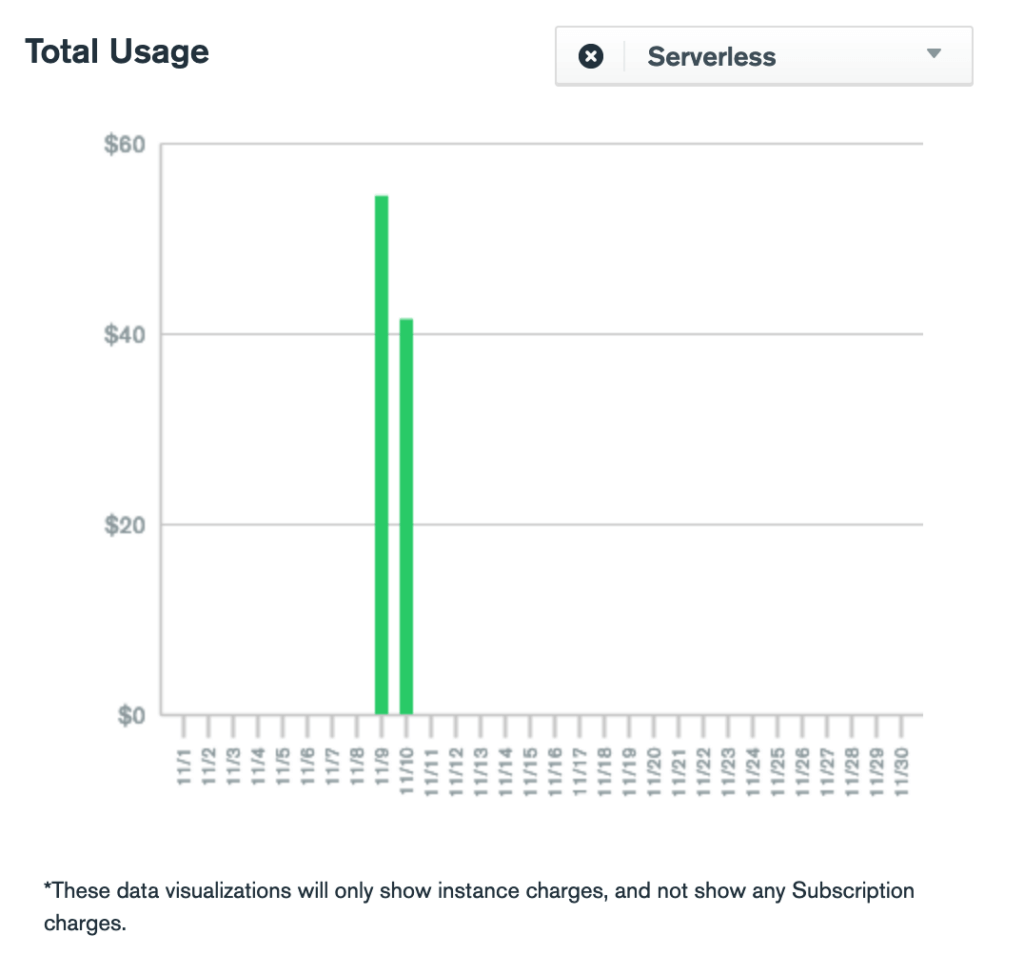
The next day I got an email. From MongoDB Atlas, alerting me that my bill had exceeded my monthly threshold of $50, which I thought I’d set pretty high! I jumped in and saw the bill for my first day was at a cool $54. That meant my monthly bill would be around ~$1,620 and a cool $19,710 a year. Yeeeesh.
Naturally I jumped into action and migrated away as quickly as possible to their free shared hosting tier, as I wasn’t going to sit around and waste time figuring out why the costs were so high.
The total bill for a day and half on MongoDB Serverless? $95.91
Why was it so expensive?
It turns out the devil is in the details (also reading helps!). A read is charged at $0.30/m if each lookup is 1 Read Processing Unit (RPU). The definition of an RPU, taken from their pricing page is:
One RPU [is a] document read (up to 4KB) or for each index read (up to 256 bytes).
https://www.mongodb.com/pricing
While for most people a 4kb is probably sufficient, be extremely careful if you have to parse “large” documents and make sure you use indexes – especially partial filter expressions – efficiently where possible.
A real life example of this is how the Chrome extension displays your unread email count in the app icon. As inboxes.app offers long lived disposable emails where the users decides when to delete an address, this query has a few parts to it:
- First we need to find the active email addresses which belong to a user in the
addressescollection. This is a simple query which makes use of an index. We read each document where enabled is true. - We then query the
messagescollection for those active addresses once again making use of indexes, and check to see if read is not null. There we count the documents and return the count.
The average address document is 163B, while the average email document is 76.8KB. That’s Math.ceil(19.2) = 20 RPU per document per 1 min lookup.
The underlying issue with this endpoint was that there were two indexes within the messages collection on the to and read keys. Spotted the issue yet? This index should have been a partial compound index with read being null. As per the MongoDB db.collection.count() documentation:
If, however, the query can use an index but the query predicates do not access a single contiguous range of index keys or the query also contains conditions on fields outside the index, then in addition to using the index, MongoDB must also read the documents to return the count.
https://docs.mongodb.com/v4.2/reference/method/db.collection.count/
What this means is that for every api call, MongoDB serverless would charge 20 RPU due to the fact that the database would have to read each document to find the read value due to an incorrectly set up partial compound index. Given that inboxes.app offers temporary disposable emails, that’s a whole lot of emails to check every minute.
How do we get out of this mess?
The obvious one is don’t be a dumb dolphin, and set up your indexes correctly. Also make sure you understand how billing works for your cloud service. Given that MongoDB is web scale and serverless is infinite, your upper bound is also infinite, so set up billing alerts.
And one final gotcha: if you do end up using a trial discount code like GETATLAS to try the service out, it’s only applied going forward. In short, if you apply the code on day 2, you’ll still get billed for day 1, and not on the final month’s bill. Very strange. Though the Atlas team were kind enough to apply it retrospectively for me.
In summary
MongoBD serverless is awesome – give it a try. You get query optimizers, index suggestions and great insight in to how your database is performing. Keep in your mind the RPUs of queries, how it will affect your billing and your overall document sizes. Saving or reading a 1MB email would again cost 250 RPU, so your application’s needs are also to be considered. As for inboxes.app, I think this essay explains why MongoDB Serverless was not a good fit for the project.
Posted on: December 18, 2021 by Inboxes